728x90
728x90
Computer Performance == TIME
- Response Time(latency)
- 프로그램이 시작해서 끝날 때까지 걸리는 시간 (time to do the task)
- 지연시간(latency)라고도 함
- Throughput
- 처리량
- 주어진 시간 당 하는 일 (tasks per unit time)
Execution Time (실행 시간)
- Elapsed Time
- disk, memory accesses, I/O 등 모든 task들의 시간을 모두 포함한 시간
- 유용한 정보이긴 하나 성능을 비교하는데 있어서는 좋지 않을 수 있음
- CPU time
- 다른 프로그램이 동작하는 시간이나 I/O 시간 등을 포함하지 않고 해당 프로그램을 사용하는데 걸린 시간만을 나타냄
- 더 구체적으로는 system time(os가 cpu 사용)과 user time으로 구분할 수 있음
- 성능 비교를 위해서 user CPU time에 초점
Definition of performance
- Performance = 1 / Execution time
- Execution time이 크다 -> 느리다 -> Performance가 좋지않다
- X is n times faster than Y -> PerformanceX / PerformanceY = n
Clock cycles
- execution time을 second로 나타내지 않고 우리는 보통 cycle로 나타낸다.
- seconds / program = (cycles / program) * (seconds / cycles)
- 프로그램이 얼마나 걸리는가 = 몇 사이클이 걸리는 프로그램인가 * 한 사이클을 수행하는데 몇 초가 걸리는가
- Clock cycle time = time between ticks = seconds per cycle (한 사이클에 몇 초?)
- Clock rate(frequency) = cycles per second(1 Hz = 1 cycle/sec) (1초에 몇 사이클?)

* update state일 때만 레지스터 등에 데이터들이 저장됨(바꾸자마자 바로 값이 바뀌는 것이 아님)
Performance를 높이는 방법
- CPU exec. Time = (CPU clock cycles / program) * Clock cycle time = (CPU clock cycles / program) * (1 / clock rate)
- 따라서, 프로그램에 필요한 cycle 수가 적을 수록, clock cycle time이 짧을수록, clock rate가 높을수록 빠르다
서로 다른 instruction은 서로 다른 수의 cycle 수를 가진다
- 예를 들어, 곱셈이 덧셈보다 더 많은 시간(cycle)이 걸린다
- 예를 들어, Floating point operation이 integer연산 보다 더 많은 시간이 걸린다
- 예를 들어, 메모리에 접근하는 instruction이 레지스터에 접근하는 instruction보다 더 많은 시간이 걸린다
- cycle time을 변경하는 것은 종종 서로 다른 instruction에서 필요한 cycle 수를 바꿀 수 있다는 것을 알아두자.
- cycle time이 줄어들면 기존 사이클 안에 Instruction을 처리하지 못해서 더 많은 사이클이 필요할 수 있다.
CPI
- Clcok cycles per instructoin
- Frequency of different instruction (Instruction Mix (multiply 1번 쓸건지, add를 여러 번 쓸건지), program)
- CPU clock cycles / program = Instruction / Program * Clock cycles per instruction
- Execution time = seconds / program = Instruction / Program * (Average) Cycles / Instruction * Seconds / Cycle
- Instruction type에 따라 영향을 받는다. (ex. CISC: 4 ~ 10 cycles, RISC: 명령어마다 다르지만 pipeline을 사용하여 보통 1 cycle에 끝남)
- CPI가 낮을 수록 좋음
MIPS
- Millions of Instruction Per Second
- 1초에 얼마나 많은 Instruction을 수행할 수 있는지
- 정확한 performance 측정 기준이 될 수 없다!
- Simple한 Instruction 10개를 1초에 실행하는 것과 Complex한 Instruction 1개를 1초에 실행하는 것 중 무엇이 더 좋다고 할 수 없다
- ex) 수행시간이 add 10 번 = mul 1 번 이라고 하면 무엇이 더 좋다고 할 수 없음.
- 프로그램을 구성하는 서로 다른 instruction이 어떻게 섞여있는지에 따라서도 달라질 수 있다.
- 개수로만 따졌을 때, multiply 10번을 수행하는 것과 add 10번을 수행하는 것의 성능이 동일하다고 할 수 없음(multiply 10 번이 더 좋을 것임)
- Simple한 Instruction 10개를 1초에 실행하는 것과 Complex한 Instruction 1개를 1초에 실행하는 것 중 무엇이 더 좋다고 할 수 없다
- 마케팅에서 활용하기도 하지만 실제 성능과 직접적인 연관은 없다
* Performance는 복합적이기 때문에 cycle 수, instruction 수 등의 영향을 받기는 하지만 이러한 요소 중 특정한 하나가 어떠한 영향을 확실히 준다고 할 수 없습니다. 그러한 요소들이 복합적으로 작용해서 performance에 영향을 주는거지 cycle 수가 반으로 줄었다고 performance가 반으로 줄거나 그러지 않습니다.
Power
- 전력 소모 또한 중요한 요소라고 볼 수 있음
- Power = Capacitive load(전하를 저장하는 축전기 수) * voltage^2 * Frequency switched
- Processor가 너무 많은 power를 소모하니 열도 많이나고 여러 문제가 나타나서 발전이 정체
- voltage를 줄여서 power를 감소하는 방식으로 발전
- 더 이상 clock을 높이지 않고 유지하며 다른 것을 향상시키는 식으로 발전
Uniprocessor Performance
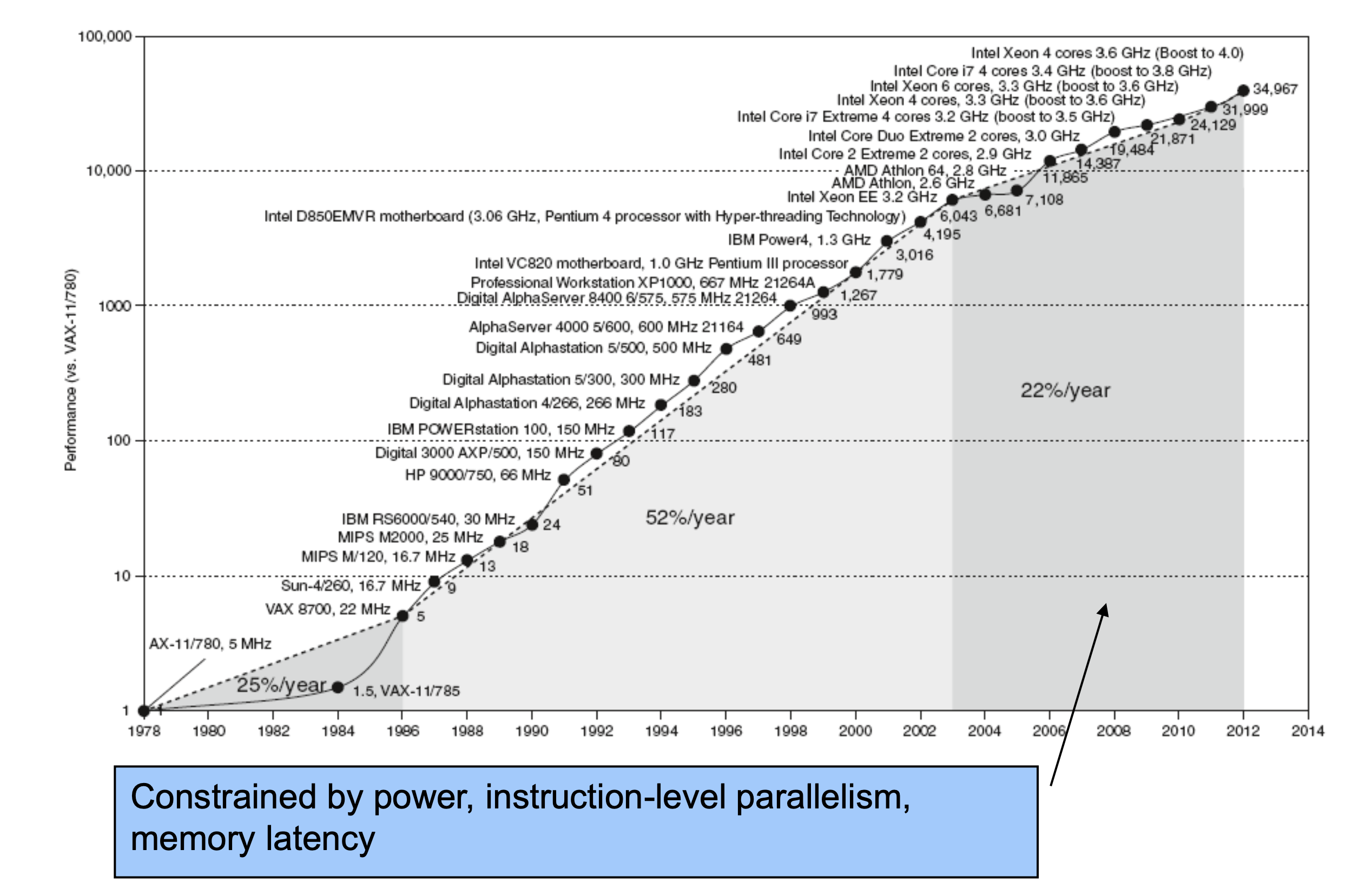
- 초기에는 single process 안에 연산장치를 여러 개 넣는 방식으로, 하나의 프로그램을 가지고 여러 개의 연상장치들이 병렬적으로 처리하는 방식으로 설계되었음
- 현대에는 process 하나 안에 복잡하게 여러 연산장치를 넣는 것이 아니라 simple 한 process를 여러 개 붙여서 multicore process를 구성하는 방식으로 설계함 ( process 각각은 simple하기에 power consumption 감소)
- 1996 ~ 2003년까지는 computer architecture 기술이 발전함에 폭발적으로 성장함
- 프로그램을 Compile해서 Machine instruction으로 만들면서 sequential한 프로그램을 만들어 사용
- 무어의 법칙에 의해서 process를 CPU로 만들어서 하나의 chip 안에 구성
- 한 번에 하나의 Instruction을 수행하는 것이 아니라 한 번에 여러 개의 Instruction을 동시에 수행할 수 있도록 구성
- ILP(Instruction-level parallelism): sequential하게 구성된 프로그램으로부터 parallel하게 연산할 수 있도록 instruction을 찾는 기술
- 2003년 이후부터 현재까지는 power 문제로 인해서 발전 정체
- ILP의 한계로 인한 정체 (아무리 줄여도 dependency로 인해서 한계가 있음(
- A의 결과를 가지고 B가 수행하는 경우, 아무리 빨리 하려고해도 A결과가 나와야만 B를 실행할 수 있는 dependency가 있다.
- 그래서 Uniprocessor가 아닌 Multiprocessor 방식으로 발전
Multiprocessor
- 하나의 칩 안에 여러개의 processor가 들어있음
- parallel programming이 필요하다. (thread을 여러 개 만들고 각 thread를 병렬적으로 처리)
- 장점
- Hardware executes multiple instructions at once
- Hidden from the programmer
- 단점
- Hard to do programming for performance
- Hard to do load balancing
- Hard to do optimizing communication and synchronization
Amdahl's Law
- Make the common case fast
- 개선에 영향을 받는 부분만 성능이 좋아지니, 미미한 부분보다는 자주 사용되는 부분에서 성능개선을 하도록 해라.
- Execution Time Unaffected + (Execution Time Affected / Amount of Improvement)
728x90
300x250
'Computer Science > Computer Architecture' 카테고리의 다른 글
| [Computer Architecture] Instructions: Language of the computer - 2 (0) | 2024.02.07 |
|---|---|
| [Computer Architecture] Instructions: Language of the computer - 1 (0) | 2024.02.06 |
| [Computer Architecture] ISA(Instruction Set Architecture) (0) | 2024.01.10 |
| [Computer Architecture] Computer improvement (0) | 2024.01.08 |
| [Computer Architecture] Computer Abstractions and Technology (1) | 2024.01.08 |