728x90
728x90
Pipeline Hazards
- Structural Hazards
- 동시에 두 가지 다른 방식으로 같은 자원을 사용하려고 시도하는 경우 발생합니다.
- Data Hazards
- 항목을 준비되기 전에 사용하려고 시도하는 경우 발생
- 명령어가 파이프라인에 있으면서 아직 처리되지 않은 이전 명령어의 결과에 의존하는 경우
- 앞쪽의 Instruction이 결과가 나오지 않았는데 뒤에 따라오는 명령어가 그 레지스터 값을 얻으려고 할 때 발생하는 hazards -> data dependency 발생
- Control Hazards
- 조건이 평가되기 전에 결정을 내리려고 시도하는 경우 발생
- branch instructions
- branch 결과가 나오기 전에는 어떤 instruction을 fetch 해야하는지 알 수 없습니다.
- Hazards는 항상 waiting으로 해결할 수 있습니다.
- pipeline control은 항상 hazard를 탐지해야 합니다.
- hazards를 해결하기 위해 조치를 취하거나 조치를 지연시켜야 합니다.
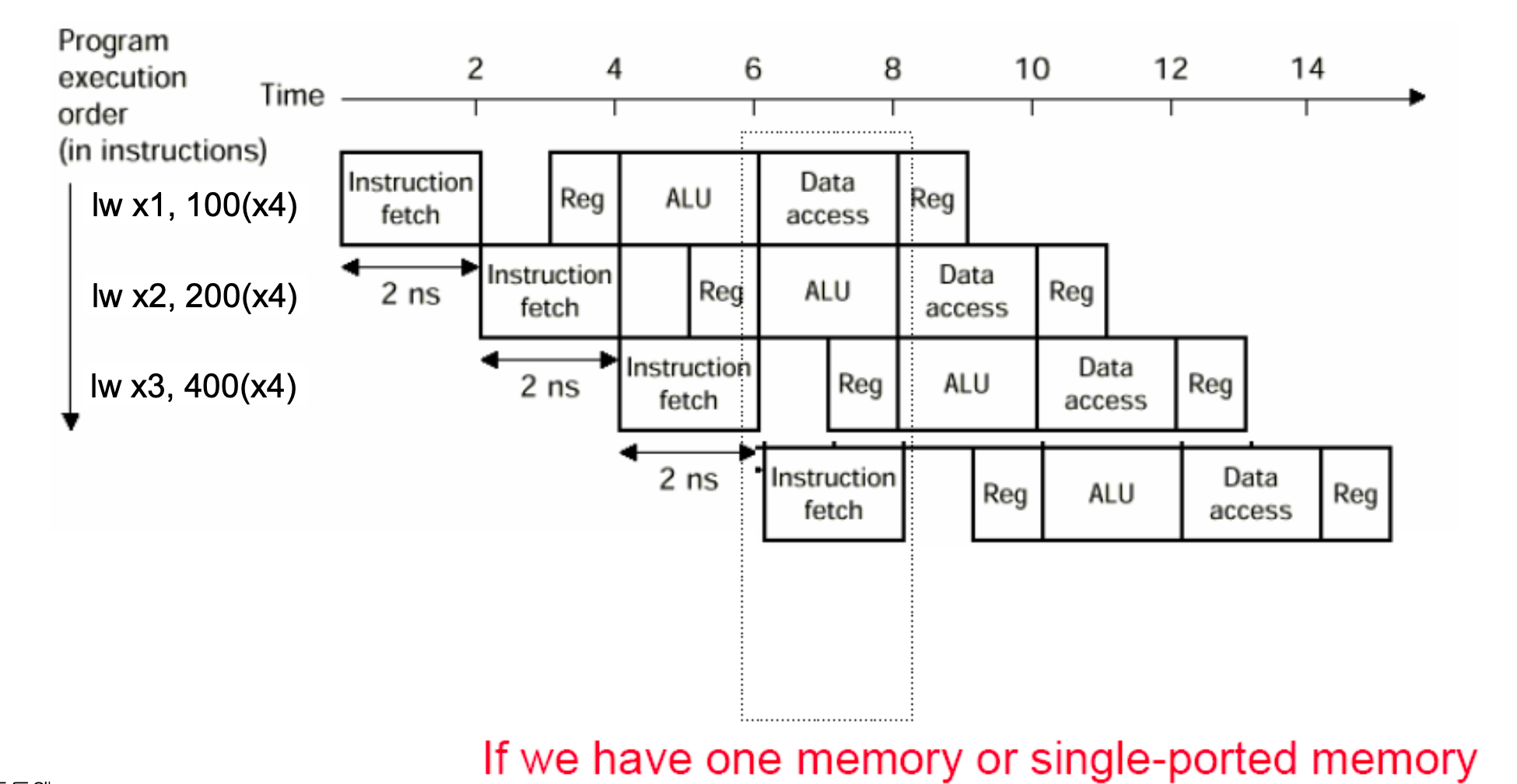
Structural Hazards
- Resource 사용의 충돌
- Single memory를 사용하는 경우, Instruction fetch가 중단되어야 합니다.
- Pipeline bubble을 유발합니다.
- 별도의 명령어/데이터 메모리(또는 캐시)가 필요합니다.
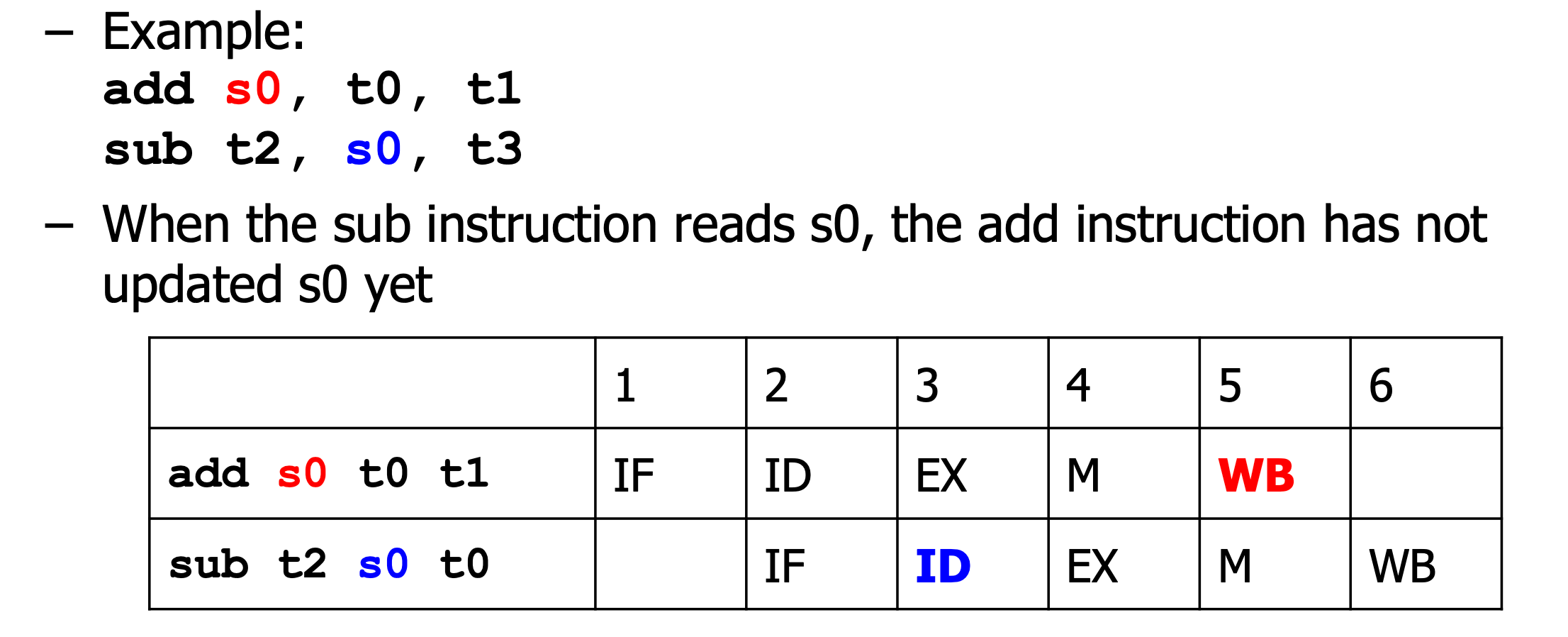
Data Hazards
- Instruction이 이전의 Instruction 결과에 의존하는 경우 발생합니다.
- Solution
- Stalling: 연관되어 있는 명령어가 끝날 때까지 기다린 후에 시작합니다. 컴파일러가 nops를 코드에 삽입해서 future instruction들을 delay 시킵니다. 성능을 저하시킬 수 있습니다.
- Forwarding: Register에 연관되어 있는 값(필요한 값)을 쓰기 전에 그 값이 계산되어 나오자마자 다음 명령어에 알려주는 방식입니다. 기본적으로는 레지스터에 쓰여져야 가져올 수 있었기에 계산되어진 값을 바로 사용할 지 말지를 결정할 수 있도록 datapath에 추가적인 연결이 필요합니다.
- 기본적인 연산들은 execution 단계가 끝나면 값을 알 수 있습니다.
- load나 store같은 경우에는 memory 단계가 끝나야지만 load나 store에 쓸 값을 알 수 있습니다.
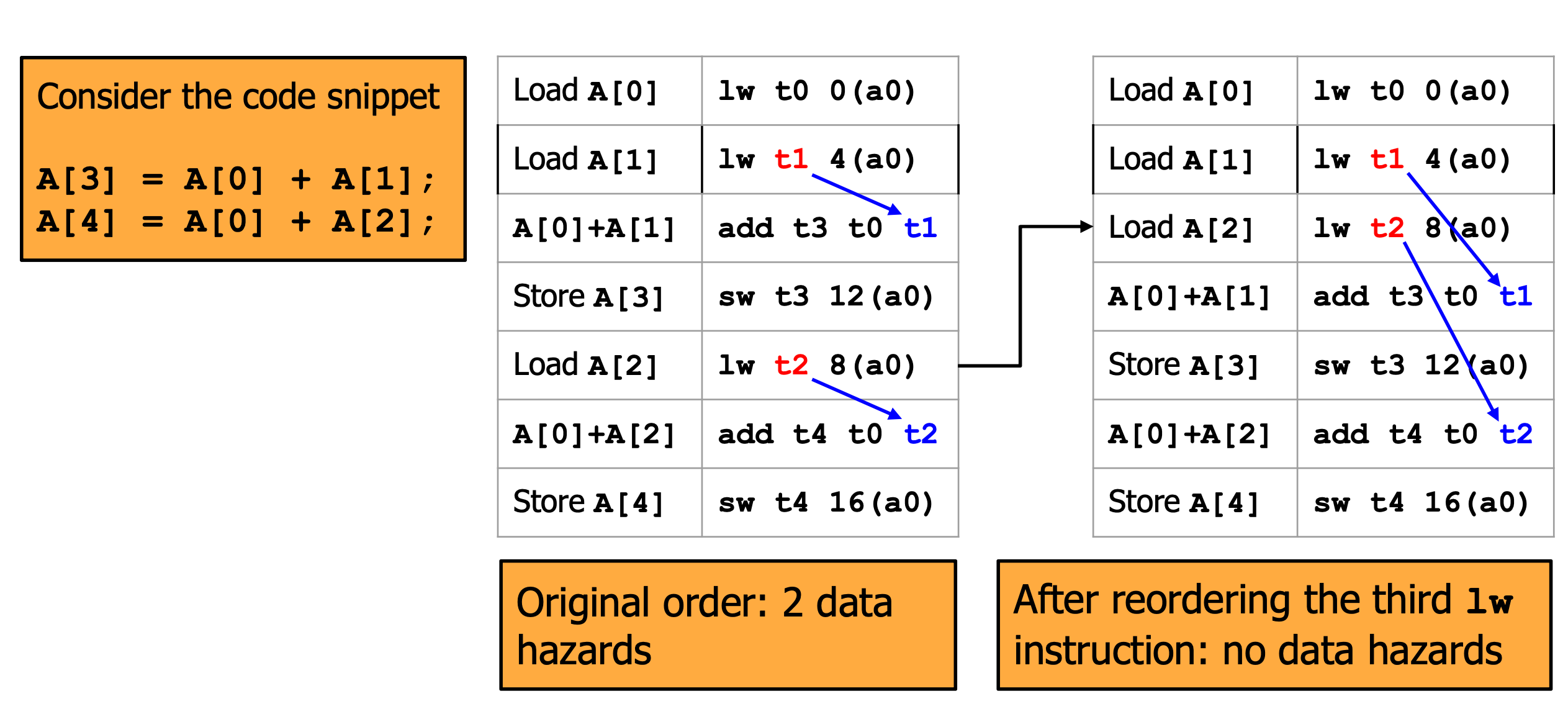
- Code Scheduling: Compiler가 결과에는 차이가 없는 한에서 Instruction들의 순서를 바꿔서 dependency가 있는 명령어들을 멀리 떨어뜨리는 것입니다.
- nop을 삽입하여 stall을 발생시키는 것은 성능을 저하시키기 때문에 forwarding까지 함께 고려하여 각 Instruction들의 거리를 적절히 떨어뜨린다면 성능 저하 없이 hazard를 방지할 수 있습니다.
- nop이 들어가야할 자리에 unrelated instruction을 삽입합니다.


Control Hazard
- 프로그램의 제어 흐름 변경(ex. branch, jump 등)으로 인해 발생합니다.
- 해결 방법
- 지연 슬롯(Delay Slot): 분기 예측이 결정되기 전에 다음 명령어(또는 명령어들)가 실행될 수 있도록, 분기 명령어 바로 뒤에 위치하는 하나 이상의 명령어 슬롯입니다.
- 분기 예측(Branch Prediction): 프로세서가 과거의 분기 패턴을 분석하여 미래의 분기 방향을 예측하는 기술입니다.
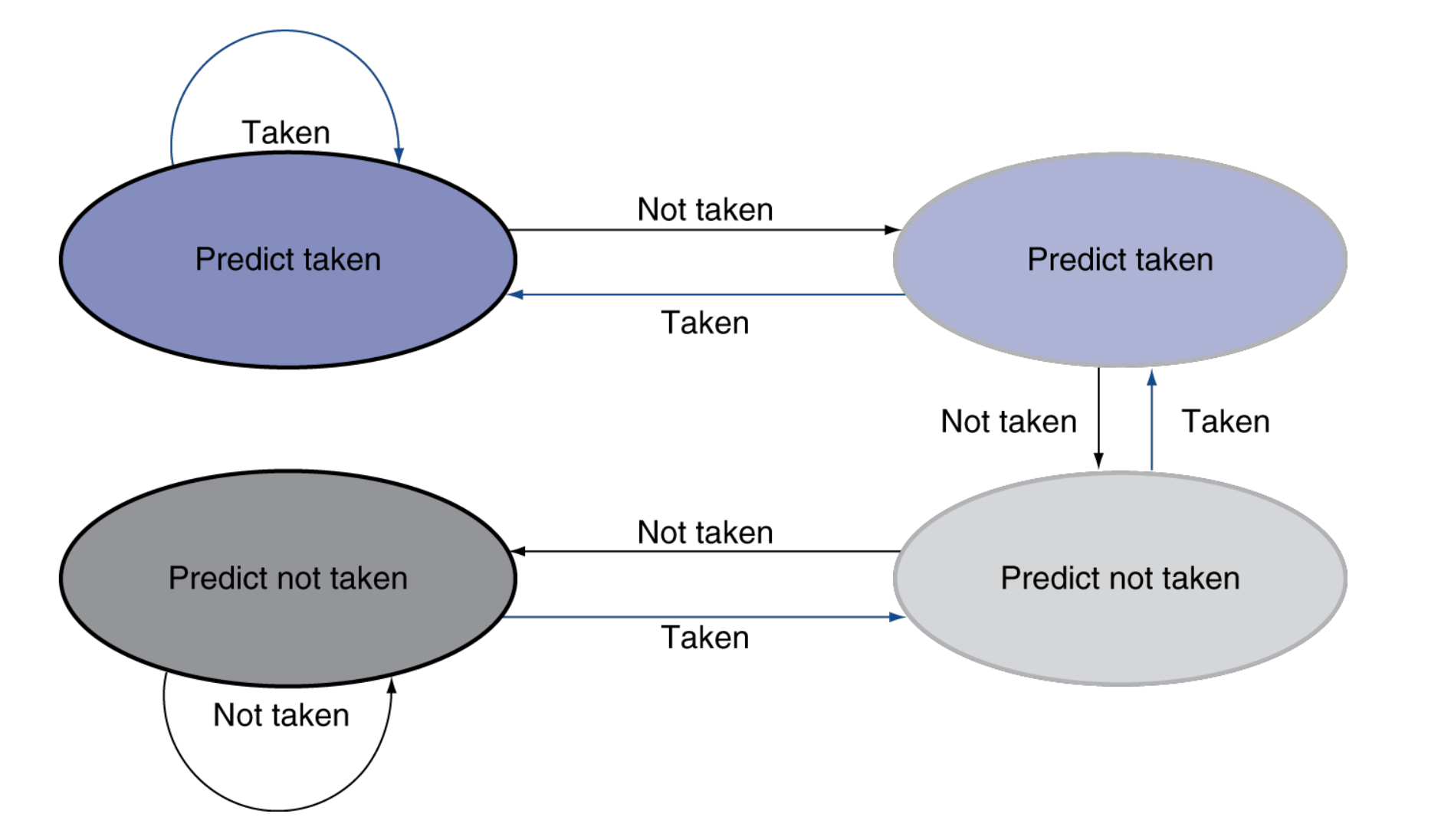
- Predict taken: 일단 branch가 taken되었다고 가정하는 방법. 가정이 맞으면 그대로 진행, 틀리면 flush
- Predict not-taken: 일단 branch가 taken되지않는다고 가정하는 방법. 가정이 맞으면 그대로 진행, 틀리면 flush. 일반적으로 taken보다는 not-taken으로 예측을 합니다. taken으로 예측하면 어디로 jump해야하는 지 그 주소를 알아야 수행할 수 있기 때문입니다. branch comparsion도 바로 하는 것이 아니라 뒷 단계에서 일어나고 jump해야하는 주소도 Execution 후에 알 수 있습니다. 따라서 taken으로 예측해봤자 주소를 바로 수행할 수 없기에 무의미한 경우가 많습니다.
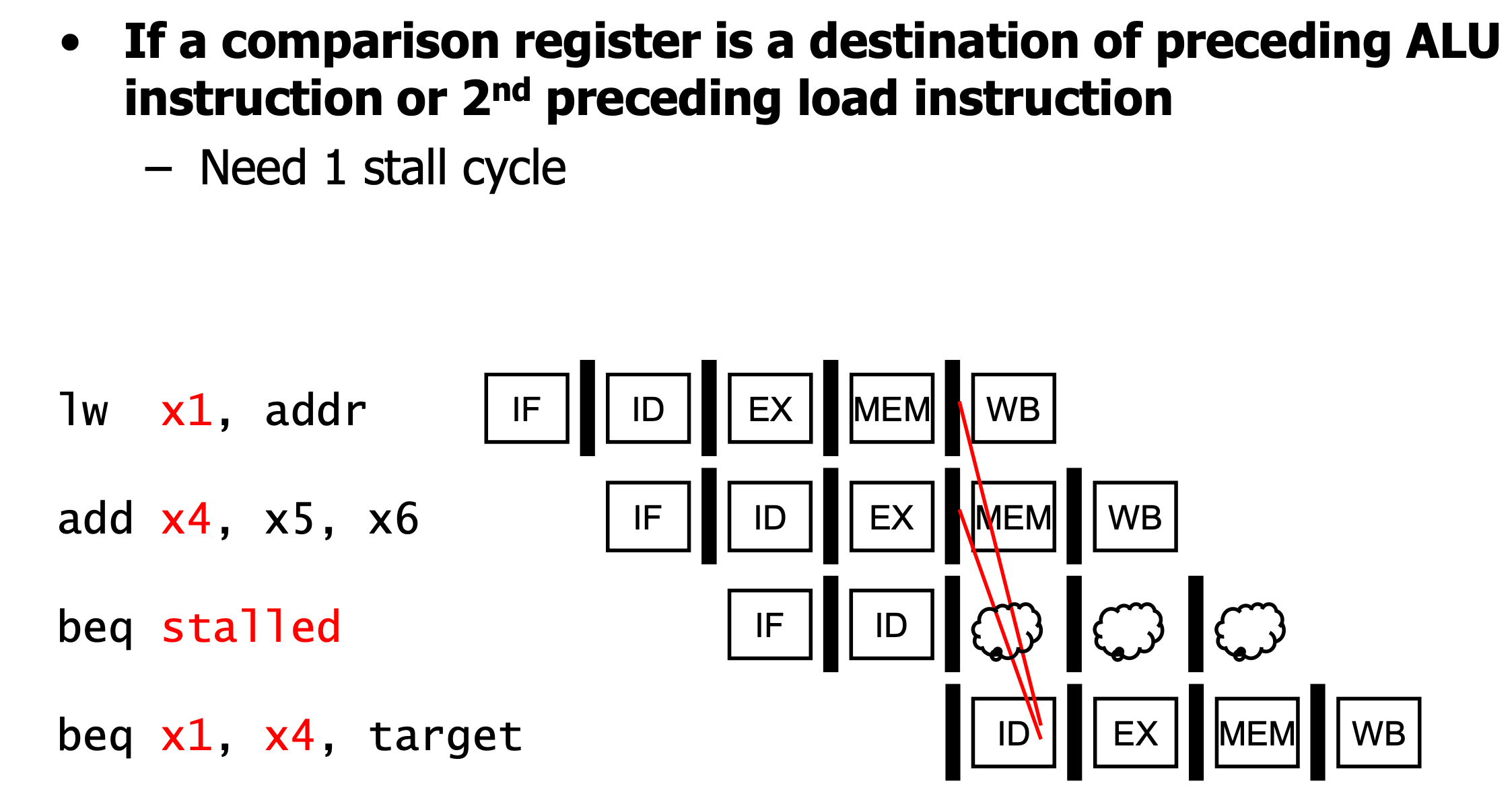
- predict not-taken에서 기존의 datapath 구조 하에서 만약 예측이 틀리면 2 cycles penalty를 가지게 됩니다. 이는 execution 단계에서 branch comparison을 하는 것이 아니라 더 빠른 단계에서 수행함으로써 패널티를 줄일 수 있습니다. Fetch는 Instruction을 가져오기만 하기 때문에 수행이 불가능하고 Decode 단계에서는 가능합니다. 하지만 기존의 ID 단계에서는 ALU가 없기 때문에 ID 단계에서 사용가능한 adder 같은 것을 추가하면서 ID 단계에서 branch 결과를 알 수 있도록하여서 패널티를 1 cycle로 줄일 수 있습니다. 하지만 Branch에서 비교해야할 값이 load, store와 연관이 있는 경우에는 이들이 계산이 될 때까지(메모리 단계)까지 기다려야 하므로 추가적인 stall cycle이 필요할 수 있습니다.
- Dynamic Branch Prediction: 위에서 얘기한 branch가 항상 not taken될 것이라고 예측하는 것은 static한 기법입니다. superscalar pipeline의 경우에는 branch penalty가 더 크기 때문에 branch prediction의 정확성을 높이는 것이 중요해졌습니다. 과거의 동작을 기반으로 미래의 branch를 예측하는 기법인 dynamic branch prediciton을 사용하게 되었습니다. Branch prediciton buffer(branch history table)이라는 최근 branch instruction addresses을 index로하는 history table을 사용하겨 결과를 저장합니다.(taken/ not taken) 이 테이블을 활용하여 같은 결과가 나올 것이라고 기대를 하고 예측을하고, 결과가 틀릴 때 pipeline을 flush하고 branch history를 업데이트를 합니다.
- 1-bit predictor: 바로 직전의 결과를 기반으로 예측. 직전의 결과가 not-taken이면 not-taken, taken이면 taken으로 예측 -> 시작은 항상 taken이고 끝은 항상 not-taken으로 끝나기 때문에 Branch의 시작과 끝에서는 항상 misprediction이 발생하는 문제.(branch에 들어가려면 1이어야 하는데, 가장 최근 사용한 branch에서 끝날 때는 0이었으니까 0으로 예측을 하고, 진행되는 중에는 계속 1인데 끝날 때 빠져나가기 위해서는 0이 나와야 하는데 1로 예측이 되어서 틀리게 됩니다.)
- 2-bit predictor: 1-bit predictor를 보완하기 위해서 두 번의 연속적인 misprediction이 나올 때만 예측을 바꾸는 방식입니다.
- 분기 목표 버퍼(Branch Target Buffer, BTB): 분기 명령어의 대상 주소를 캐싱하여, 분기 명령어가 다시 등장할 때 빠르게 대상 주소를 얻을 수 있도록 하는 기법입니다.
- 조건부 실행(Conditional Execution): 명령어가 조건에 따라 실행되거나 실행되지 않도록 함으로써, 불필요한 분기를 줄이는 방법입니다.



Forwarding
Forwarding은 파이프라인 내에서 나중의 명령어가 이전 명령어의 결과를 기다리지 않고 즉시 사용할 수 있도록 하는 기술입니다. 예를 들어, 첫 번째 명령어가 레지스터 A에 값을 쓰고, 바로 다음 명령어가 그 값을 읽어야 하는 상황을 가정해 봅시다. 이 경우, 첫 번째 명령어의 실행 결과가 아직 메모리에 쓰여지지 않았더라도, 그 결과를 파이프라인의 뒷부분으로 "전달"하여 두 번째 명령어가 즉시 사용할 수 있게 합니다. 이로써 데이터 의존성으로 인한 지연을 줄일 수 있습니다.
Bypassing
Bypassing은 forwarding과 매우 유사한 개념으로, Data hazard를 해결하는 또 다른 방법입니다. 일부 문헌에서는 forwarding과 bypassing을 동의어로 사용하기도 합니다. Bypassing은 실행 단계에서 필요한 데이터가 이전 명령어의 결과일 경우, 그 데이터를 메모리에 쓰고 다시 읽는 대신에 직접 해당 데이터를 다음 명령어로 "우회 전달"하는 기술입니다. 이는 Data hazard를 줄임으로써 파이프라인의 효율성을 높이고, 실행 속도를 개선합니다.
728x90
300x250
'Computer Science > Computer Architecture' 카테고리의 다른 글
| [Computer Architecture] Exceptions (0) | 2024.03.03 |
|---|---|
| [Computer Architecture] Hazard Detection (0) | 2024.03.03 |
| [Computer Architecture] Enhancing Performance with Pipelining (0) | 2024.03.03 |
| [Computer Architecture] Datapath (0) | 2024.02.29 |
| [Computer Architecture] Clocking Methodology (1) | 2024.02.29 |